
카이도스의 Tech Blog
PKOS 6주차 - Alerting 얼럿매니저 로깅시스템 본문
쿠버네티스 공부는 ‘24단계 실습으로 정복하는 쿠버네티스 책을 기준으로 진행.
이번 6주차에서는 AlertManager와 PLG 스택을 공부한다.

alertmanager 란 - 링크1, 링크2, 링크3
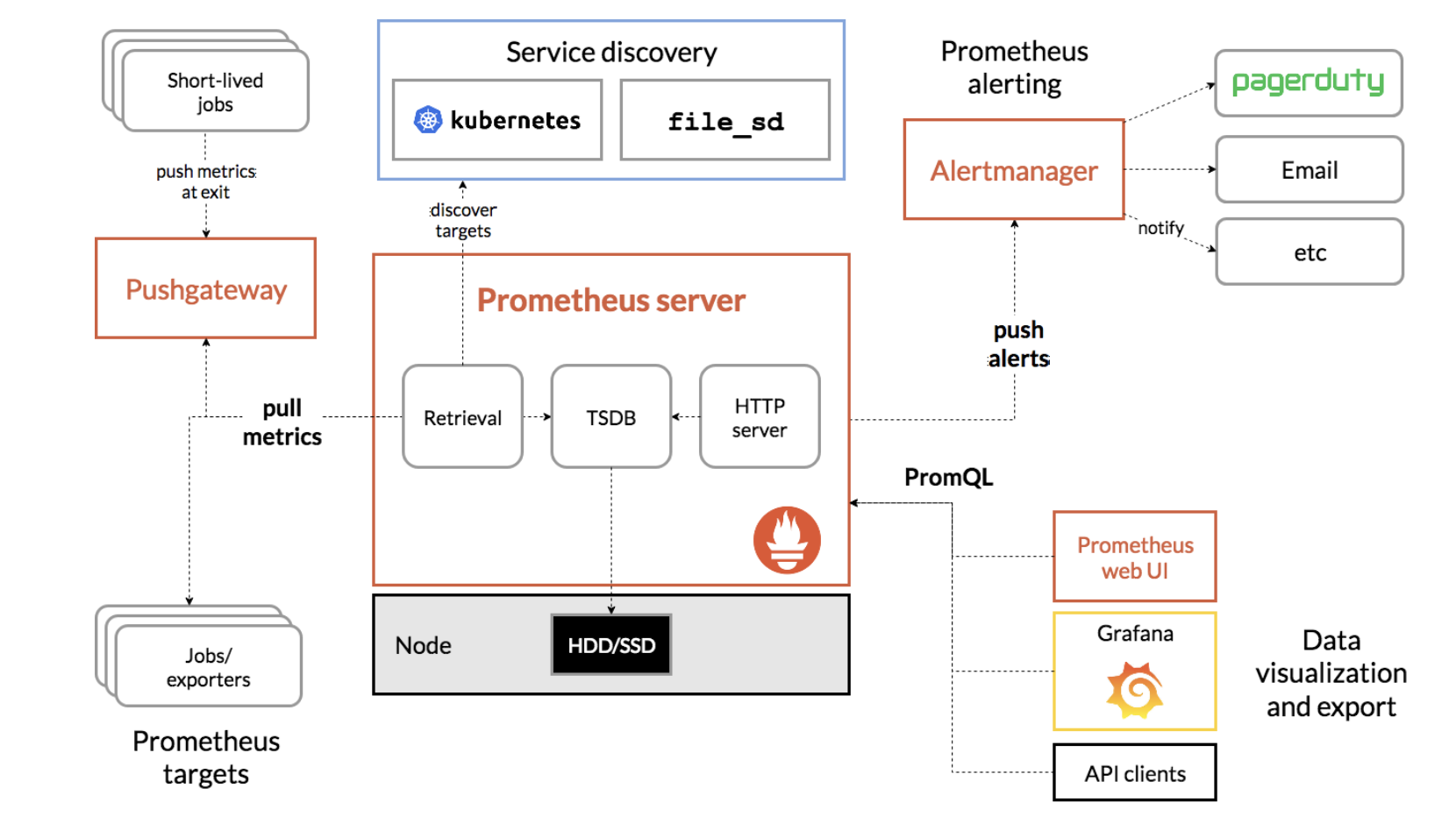
쿠버네티스에서 모니터링 시스템을 구축한다면 대부분의 경우 프로메테우스를 사용하게 된다. 하지만 프로메테우스만 사용하는 경우는 거의 없고, 보통은 Grafana, AlertManager, Thanos 등과 같은 솔루션을 연동해 함께 사용하는 것이 일반적이다. 그 중에서도 AlertManager는 프로메테우스의 메트릭 변화에 대한 알림을 전송하는 역할을 담당하는데, 프로메테우스 메트릭을 통해 특정 이벤트를 인지하고 메시지를 전송해준다는 점을 생각해 보면.. 어찌보면 장애 대응에 있어 가장 중요한 도구라고도 볼 수 있다.
prometheus 를 통해 수집된 metric에서 사전에 설정해둔 alert rule 에 해당하는
이벤트가 발생하면 alertmanager 에게 알림이 가고
alertmanager는 이 알람을 email,slack, web-hook 등 다양한 방법으로 전달하는 역할을 한다.
사실 dashboard 역할을 하는 grafana도 4.x 버전대 부터는 이 알람기능이 추가 되었는데
UI상에서 정말 쉽게 알람 설정을 할 수 있다는 장점이 있지만
host 마다, metric 마다 일일이 설정해야 한다는 단점이 있어 모니터링 해야하는 대상이 많을 땐 역시 alertmanager 가 더 좋은 것 같다.

실습환경 구성
kops 인스턴스 t3.small & 노드 c5.2xlarge (vCPU 8, Memory 16GiB) 배포 및 kops 인스턴스(t3.small)에 SSH 접속 : 이번주 실습에서 성능을 요구하는 파드를 사용함
EC2 instance profiles 설정 및 AWS LoadBalancer 배포 & ExternalDNS & Metrics-server 설치 및 배포 : 20~30분 정도 소요
# EC2 instance profiles 에 IAM Policy 추가(attach)
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name nodes.$KOPS_CLUSTER_NAME
# kOps 클러스터 편집 : 아래 내용 추가
# kubeproxy.metricsBindAddress 설정은 프로메테우스 kube-proxy 메트릭 수집을 위해서 설정 : 기본값 127.0.0.1 -> 수정 0.0.0.0 - 링크
kops edit cluster
-----
spec:
certManager:
enabled: true
awsLoadBalancerController:
enabled: true
externalDns:
provider: external-dns
metricsServer:
enabled: true
kubeProxy:
metricsBindAddress: 0.0.0.0
-----
# 업데이트 적용 : 모든 노드 롤링업데이트 필요 >> 마스터 EC2인스턴스 삭제 후 재생성 후 정상 확인 후, 워커노드 EC2인스턴스 생성 후 Join 후 삭제 과정 진행됨
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster --yes
# EC2 인스턴스 모니터링
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done[과제1] 책 367~372페이지 - 사용자 정의 prometheusrules 정책 설정 : 파일 시스템 사용률 80% 초과 시 시스템 경고 발생시키기 ⇒ 직접 실습 후 관련 스샷을 올려주세요

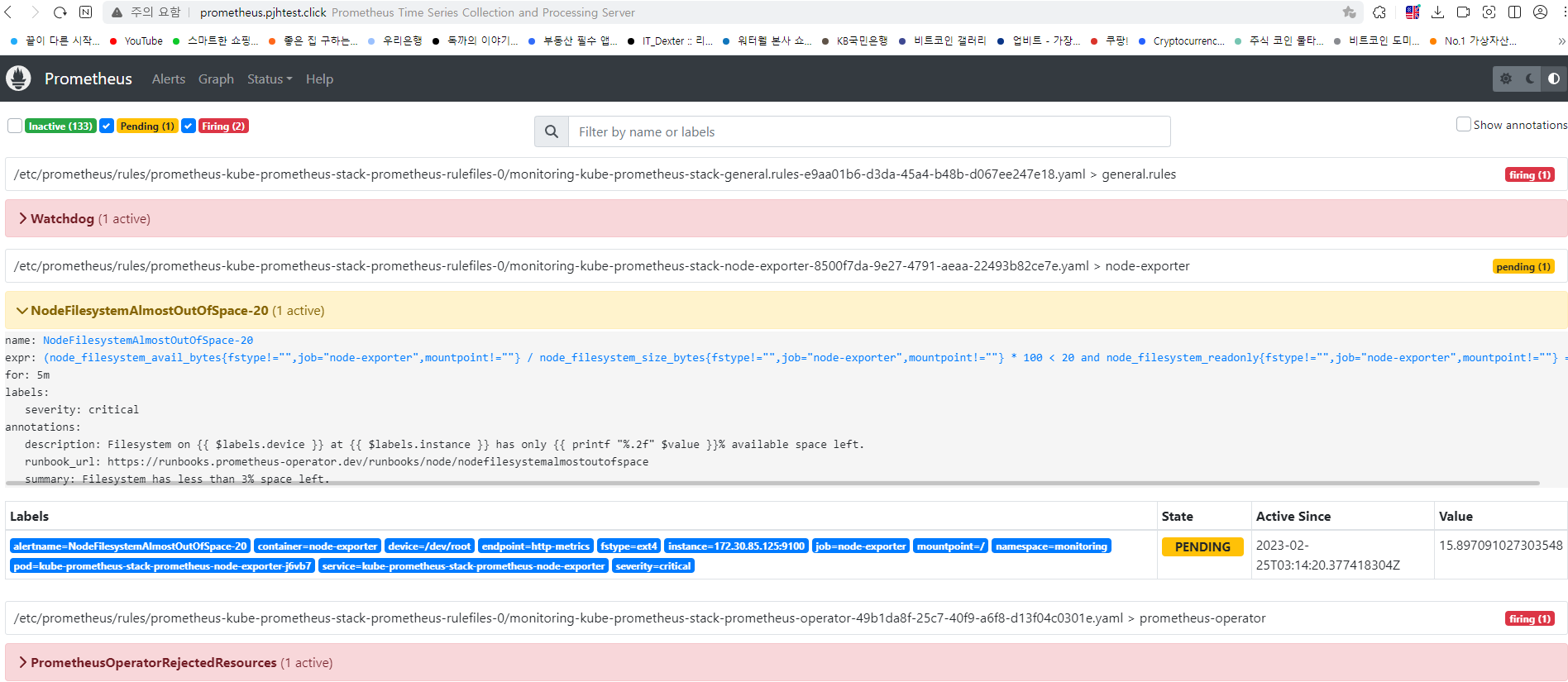
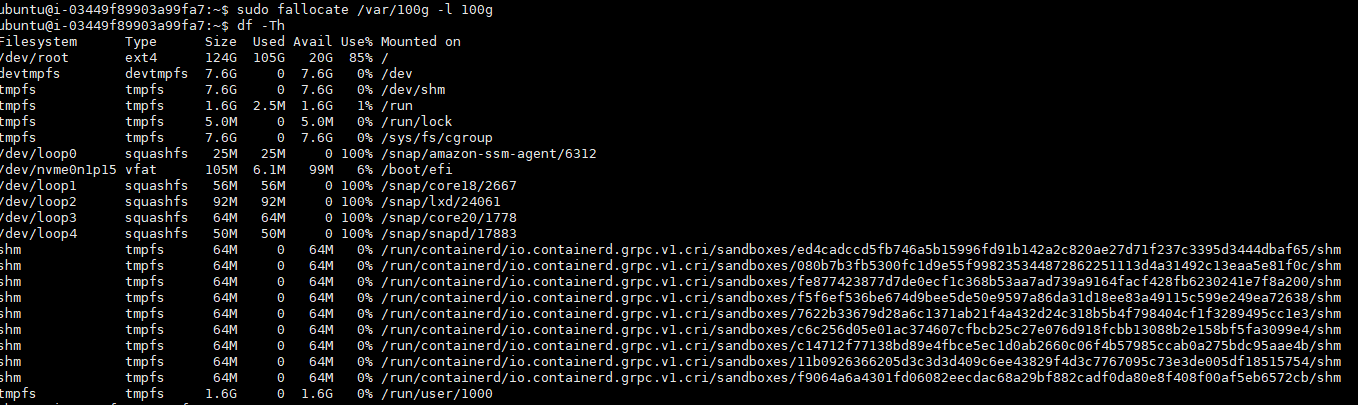
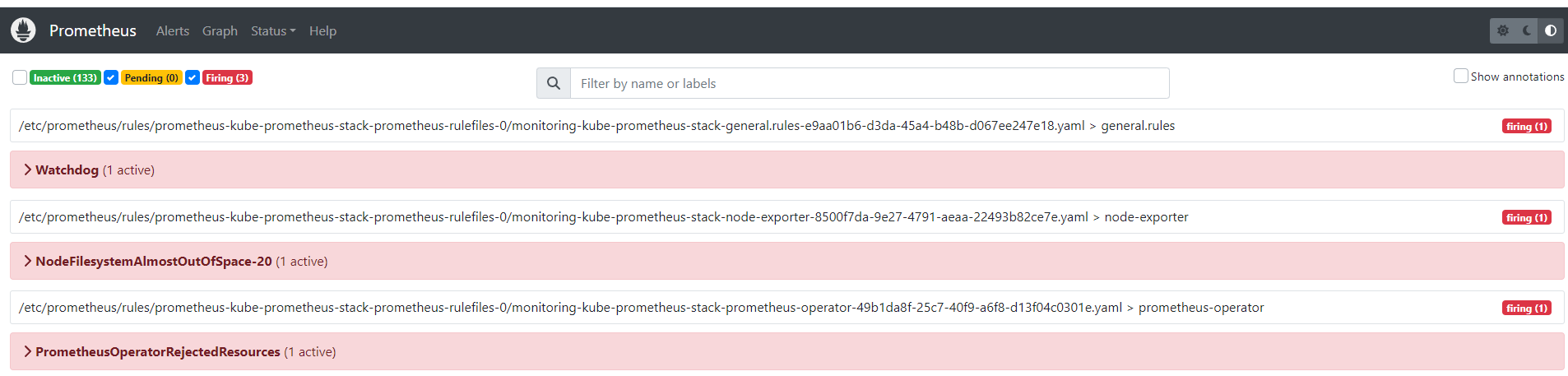
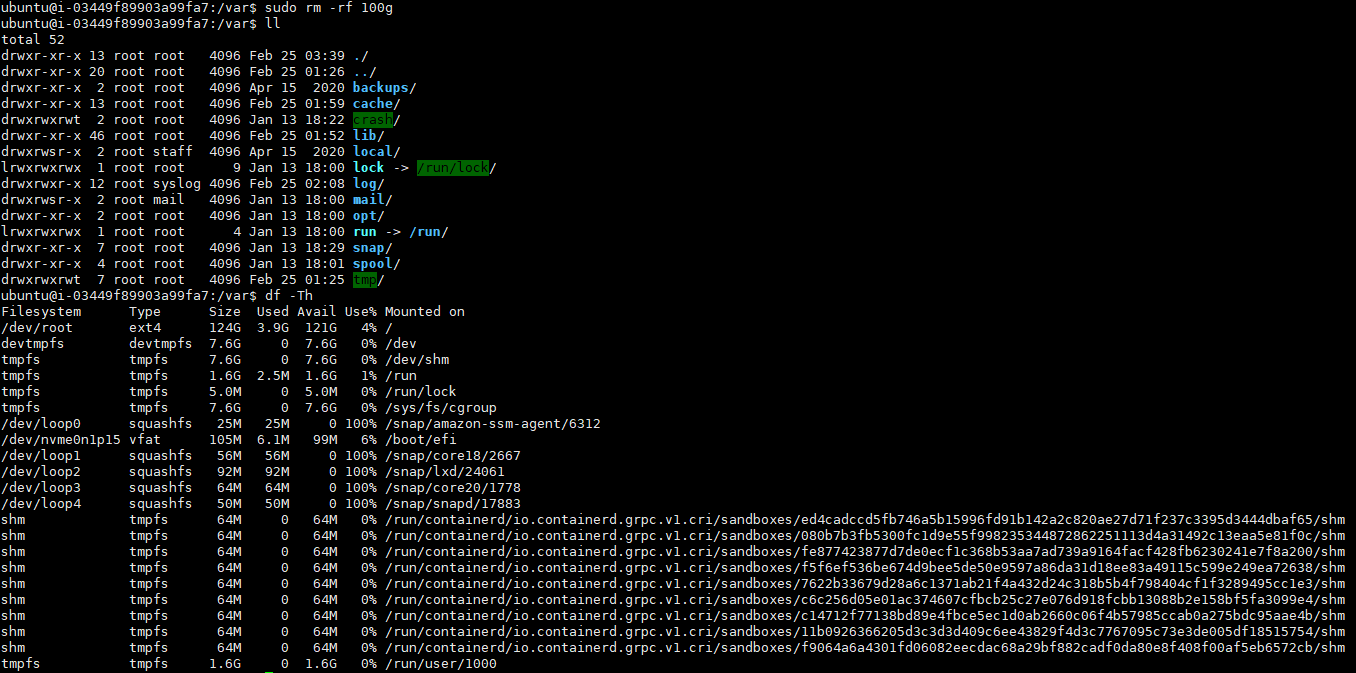
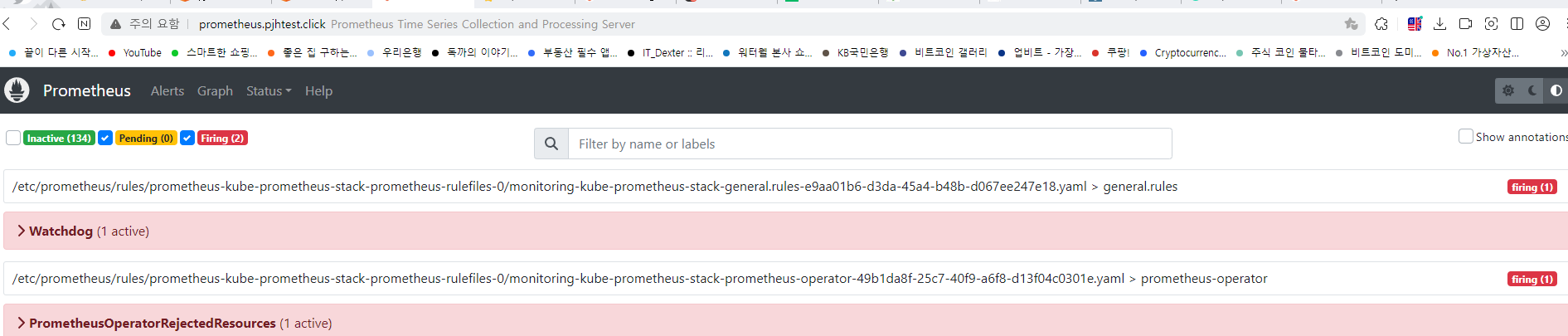
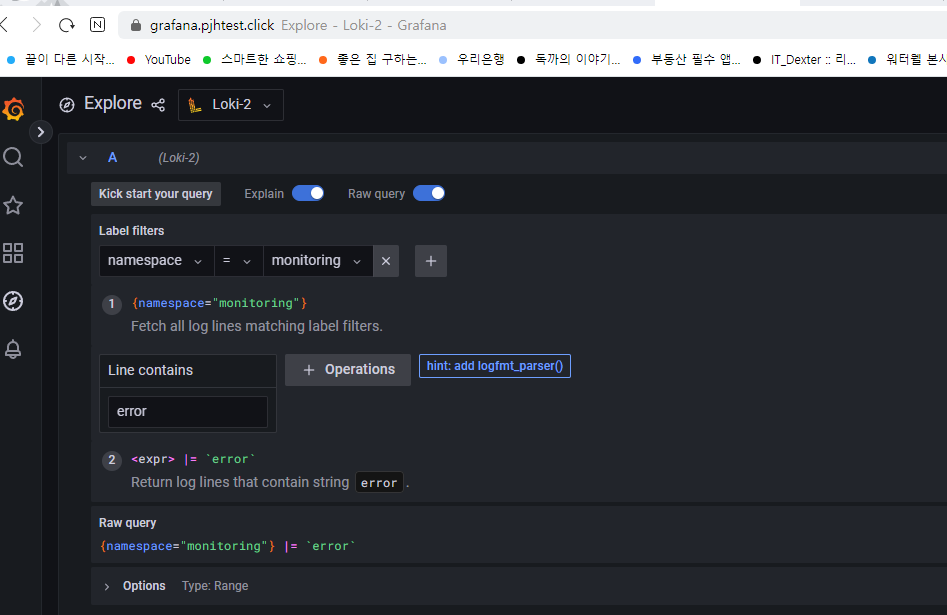
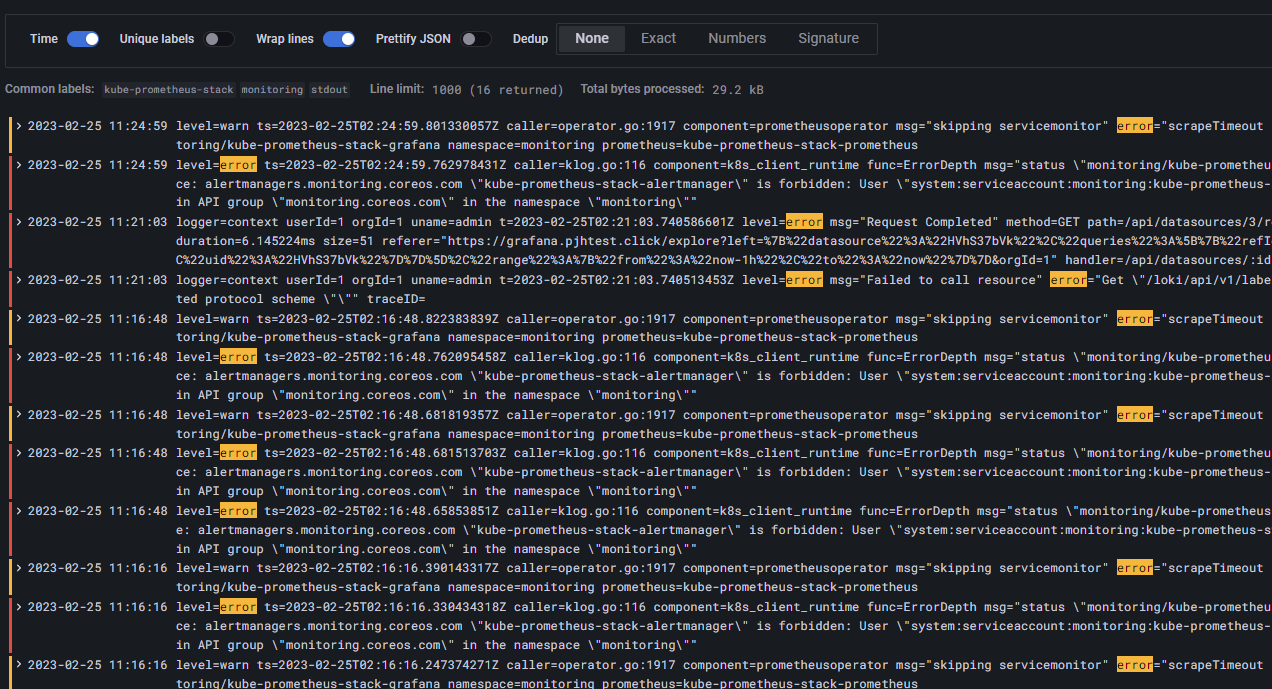
[과제2] 책 386~389페이지 - LogQL 사용법 익히기 ⇒ 직접 실습 후 관련 스샷을 올려주세요
Label filters → namespace → monitoring → Line contains → error검색
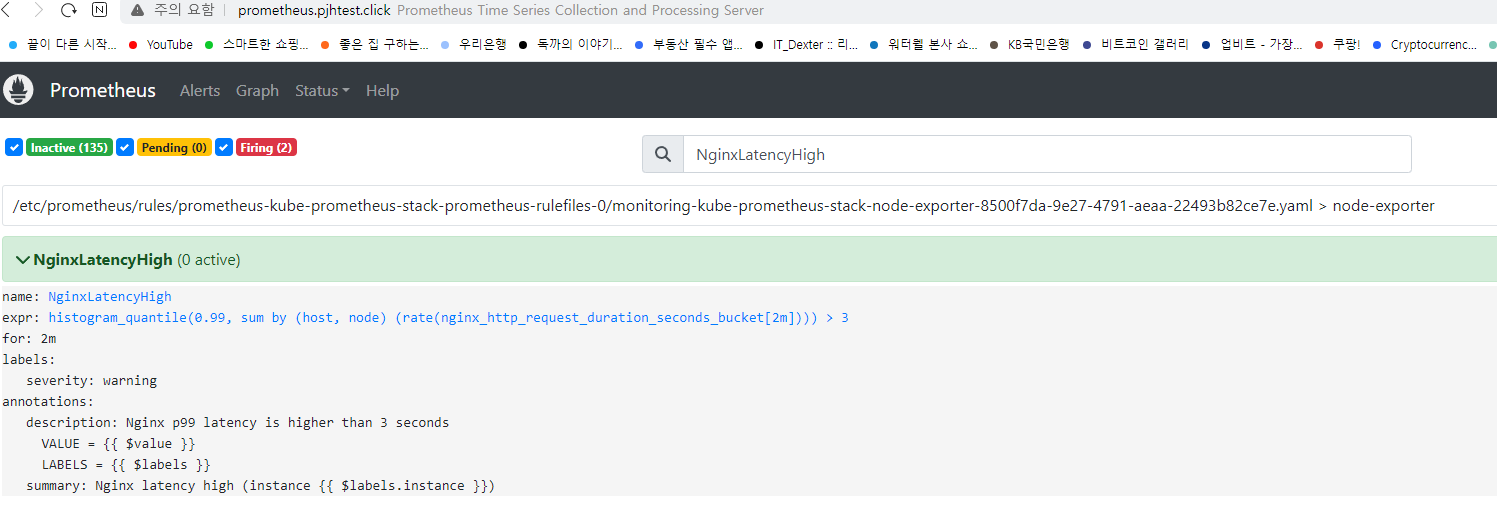
[과제3]Awesome Prometheus alerts 를 참고해서 스터디에서 배우지 않은 Alert Rule 생성 및 적용 후 관련 스샷을 올려주세요
https://awesome-prometheus-alerts.grep.to/rules#nginx 해당링크 참조하여 yaml 수정 진행

'KOPS' 카테고리의 다른 글
| 쿠버네티스 kubespray 설치 (0) | 2023.03.14 |
|---|---|
| PKOS 7주차 - 보안 (0) | 2023.02.27 |
| PKOS 5주차 - 프로메테우스 그라파나 (0) | 2023.02.14 |
| PKOS 4주차 - Harbor Gitlab ArgoCD (0) | 2023.02.07 |
| PKOS(쿠버네티스)3주차 - Ingress & Storage (0) | 2023.02.01 |


